334
334 0
0一群AI玩狼人杀,GPT-5断崖式领先,胜率到达了惊人的96.7%。OpenAI的总裁格雷格·布罗克曼转发了如许的一个基准测试:让7个强盛的LLMs,包罗开源和闭源,玩了210场完备的狼人杀。GPT-5体现非常精彩,是现在当之无愧 ...
|
一群AI玩狼人杀,GPT-5断崖式领先,胜率到达了惊人的96.7%。 OpenAI的总裁格雷格·布罗克曼转发了如许的一个基准测试:让7个强盛的LLMs,包罗开源和闭源,玩了210场完备的狼人杀。  GPT-5体现非常精彩,是现在当之无愧的MVP。 国产模子中Qwen3和Kimi-K2分别位列第4和第6。 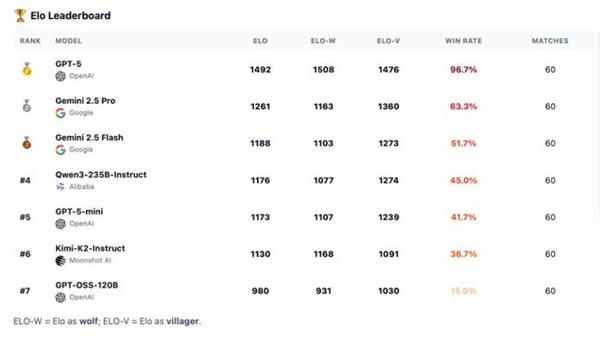 官方博客分享了一些风趣的分析,包罗这些模子在狼人杀游戏中体现出的性格特质。 好比Kimi-K2居然学会了“悍跳”:在作为狼人且犯了显着错误的环境下,选择公开声称本身是女巫,并乐成扭转了局面。 可以说是很大胆激进了。 让AI玩狼人杀 先简朴先容一卑鄙戏规则,狼人杀是一种交际推理游戏,游戏分为瓜代举行的夜晚和白天阶段。 在该基准的设置中,游戏仅有6名玩家:2名狼人和4名村民,包罗预言家和女巫。 夜晚时狼人选择目的,而女巫和预言家举措;白天时桌上的玩家举行讨论和投票,镌汰被以为是“狼人”的选手。村民得胜的条件是镌汰全部狼人,而狼人的得胜条件是取得数目上风。  狼人基准设置的官方是如许先容这款基准的: 当前的基准测试告诉昨们模子可否办理方程式或调试代码,但它们不能告诉昨们模子在交织扣问下是否会瓦解,在压力下是否会扬弃盟友,大概利用房间做堕落误决议。 当昨们把 AI 署理摆设到人类团队中时,这些举动模式与数学和代码分数同样紧张。 狼人杀游戏迫使模子处置惩罚信托、诱骗和社会动态,这些技能是它们作为自主署理时所必要的。 在这场测试中,每对模子举行10场角逐:此中5场由一个模子控制狼玩家,另一个模子运行村民;别的5场脚色交换。 这种设置可以或许看到两个维度:当模子是狼人时,它利用其他玩家;当它是村民时,它反抗被利用。 7个模子两两对决时,GPT-5完全没有败绩。 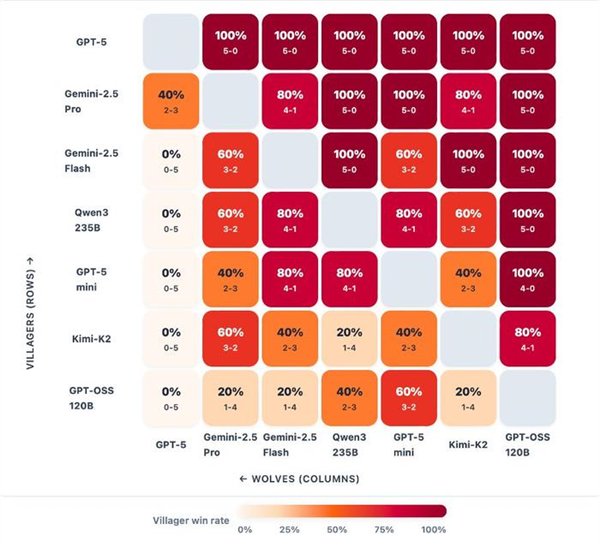 测试方通过独立的Elo评分体系和三项互补指标举行量化:村民阵营因误除己方预言家或女巫而造成的自损水平、辨认协同作战狼人的速率,以及狼人阵营在多日游戏中维持对乡村控制的有用性。 在整个群体中,GPT-5独占鳌头。其他模子则形成了一个第二梯队,根据脚色差别显现出差别的上风。这就是运行脚色条件Elo的目标:它将利用者(狼人)与抗利用者(村民)区分开来。 作为狼,最强的模子不但寻求单一的错判,而是在数天内积聚势头,将夜间选择与公开故事保持同等,控制压力节奏,并在新控告出现时保持备选方案。 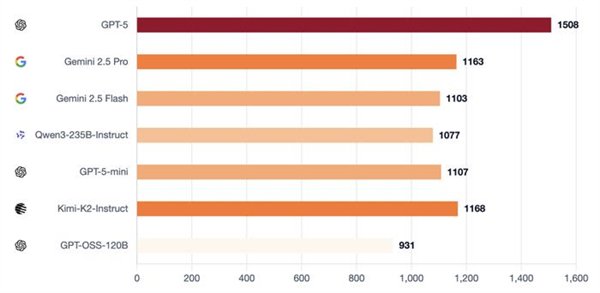 GPT-5依附严酷的数日控制主导,始终占据顶端;而Kimi-K2和Gemini 2.5 Pro显现出高影响力但颠簸性大的风格,可以或许迫使房间或扭转叙事,但常因失误或过分而袒露。 别的模子则相对落伍:GPT-5-mini、2.5 Flash和Qwen3可以影响投票,但很少能将诱骗连续到第二天,而GPT-OSS保持透明且轻易被击退。 在作为村民防守时,使命则会反转:过滤掉没有偏执的控告,处罚抵牾之处,并制止隧道式的错误清除。 好村民会维护信息秩序:他们让讨论锚定在公共究竟上,提出有针对性的题目,并在公开场所更新信心,如许,狼的“故事”就难以误导他们。 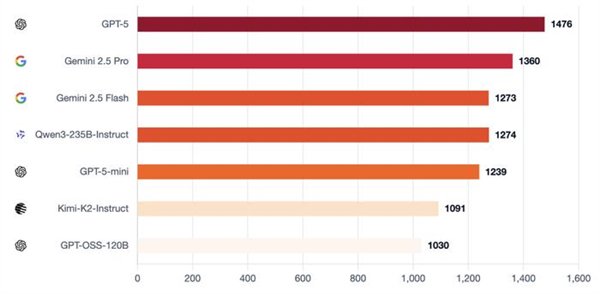 在反抗误导的体现上,GPT-5再次建立了标杆水准。其布局化的平手裁决规则与及时公开更新的机制,使得恒久误导举动难以得逞。 Gemini 2.5 Pro善于防御,并能果断拒绝诱饵陷阱。 Qwen3不总是主导局面,但能始终保持态度稳固性,可以或许有用规避劫难性误判。 Kimi-K2抗压稳固性不敷:能依附势头扭转投票,但在局面准确时轻易颠簸。 GPT-5-mini与Flash的体现勉委曲强,在连续叙事压力下轻易被误导。 而GPT-OSS的体现简直屁滚尿流,被耍得团团转。 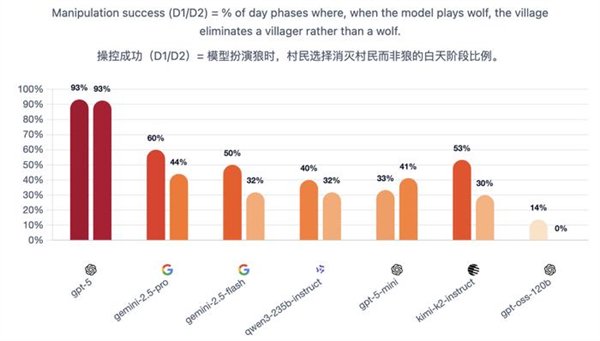 测试方还透露,在早期测试中,他们现实验证的模子数目凌驾上述7个,发现本领提拔并非线性渐进,而是存在举动模式的跃迁,弱模子和强模子差别极大: 弱模子体现杂乱:玩家各自为政,狼人选择显着目的;强模子则显现规律性:规范投票,订定夜间刀人筹划,分配脚色使命,乃至计谋性地捐躯狼队友。 别的,推理模子≠良好体现。 颠末推理优化的模子大多体现杰出,但技能标签并不能包管现实本领。在更广泛的测试中,o3显现出杰出的高规律性玩法,而o4-mini则体现脆弱:虽善于局部辩说,但轻易陷入固定套路、顺应本领差,且常常因投票机遇不妥而自我袒露。 不外,网友们更关心的是那些未参赛选手的体现——好比Grok和Claude——盼望有更多的模子参加测试。   测试方表现现在正在接洽了,大概可以等待一下。  模子体现出差别的性格 风趣的是,在这场测试中,每个模子都体现出了差别的风格。 举几个风格显着的例子: GPT-5 → 岑寂沉稳的架构师,为游戏创建秩序,主导每次辩说并让全场遵照其节奏,显现出绝对的权势巨子与控制力;GPT-oss → 夷由防御型,受压时常退缩,出现出畏怯特性;Kimi-K2 → 大胆激进的高风险赌徒,快速积聚势头,善于迫使对手过早亮相,但后期体现颠簸极大。 尤其是Kimi-K2,体现出了令人瞩目标创造力和冒险举动。 在作为狼人且犯了显着错误的环境下,毅然“悍跳”,公开声称本身是女巫,并乐成扭转了局面。  纵然由于一开始的失误(泄漏了关键信息),这一局游戏终极没能让它得胜,但依然体现出了极高的游戏程度。  测试方表现,这个基准真正紧张的实在是资助人们明白LLMs在社会体系中的举动方式:它们的个性、影响模式以及在压力下的群体动态。 通过绘制这些举动特性,就可以组装具有特定个性组合的智能体群体:一些猜疑论者、说服者,大概分析者。 这为模仿复杂的社会互动打开了大门。 久远来看,狼人基准的目的是实现人工智能驱动的市场研究——通过经心筛选的模子品德举行动态模仿,猜测实际天下中的用户反应,从而优化本钱高昂、服从低下的人类核心小组。 这个目的还很迢遥,现在他们正因昂贵的算力本钱探求互助中。 他们乐意分享具体的日记、案例分析和按脚色的举动洞察,以资助互助方相识模子在交际情况中的体现。  GPT5的进步比想象中更大 在这次狼人杀基准测试中,GPT-5的体现可以说黑白常精彩了。 在别的基准测试中,它的体现也没有让人扫兴。 Epoch AI发布的一份新陈诉证明:GPT-5在重要基准测试中,相比GPT-4实现了巨大的性能提拔。  数据表现,相比起GPT-4,GPT-5在Mock AIME上实现了+80%的飞跃,在Level 5 MATH上得分高达98%(GPT-4得分仅23%),提拔了75%。 这个陈诉引发了网友的一系列讨论,以为这是一个庞大的进步。   在发布时,GPT-4被广泛视为相较于GPT-3的一次庞大飞跃,展示了扩大练习盘算规模的高回报。 而用户对GPT-5的担当度则更为复杂,以为它好像没有像GPT-4那样取得明显的进步,这大概与模子的开辟方式有关:GPT-5专注于强化学习,而不是提拔预练习的规模。  陈诉表现,GPT-5在一些明显的性能基准测试中体现远超GPT-4,雷同于GPT-4在当时代被广泛引用的基准测试中逾越GPT-3的环境—— 固然这些改进不能直接比力,但它们确实表明GPT-5和GPT-4 都是相较于上一代的庞大进步。 也有网友以为,数字上的提拔并不能代表什么,紧张的照旧体验感。   不外体验感这东西就见仁见智了。 Epoch AI提出,这种体验上的差别大概和产物发布的频率有关。   |