智东西AI前瞻(公众号:zhidxcomAI) 作者 | 江宇 编辑 | 漠影 智东西AI前瞻7月18日报道,本日破晓,OpenAI正式推出了ChatGPT Agent,一个整合了网页交互、深度检索和代码本领的全新“AI助手形态”。 从产物逻辑上看,网络交互工具Operator和深度信息检索工具DeepResearch不再分家,ChatGPT内部出现了一个可以或许“查找-思索-实行”一体化的Agent,用户能直接让AI跨网页、代码、个人数据源完成完备使命。 相较于OpenAI接连被挖角引发的舆论热度,ChatGPT Agent的发布似没到达“革命性Agent”的期许,略显反应平庸。社区用户体验后批驳不一,有人以为“初见AGI的雏形”,但也有人指出PPT排版大略、复杂逻辑易停止和幻觉等题目。 ChatGPT Agent发布后,竞品Manus第一时间接招,放出10个实测案例,试图通过财政建模、生存规划、行程安排、消耗购物、航班筛选等差别场景使命,证实ChatGPT Agent在使命闭环和可视化交付上并不占优。
▲(图源:Manus X平台) 回过头来看,ChatGPT Agent在网页欣赏、实行使命等多个测评中实现了SOTA,在“人类的末了测验”(Humanity’s Last Exam)测试中取得了41.6的高分。这一结果证明白其本领,也同时必要进一步在真实场景中验证。
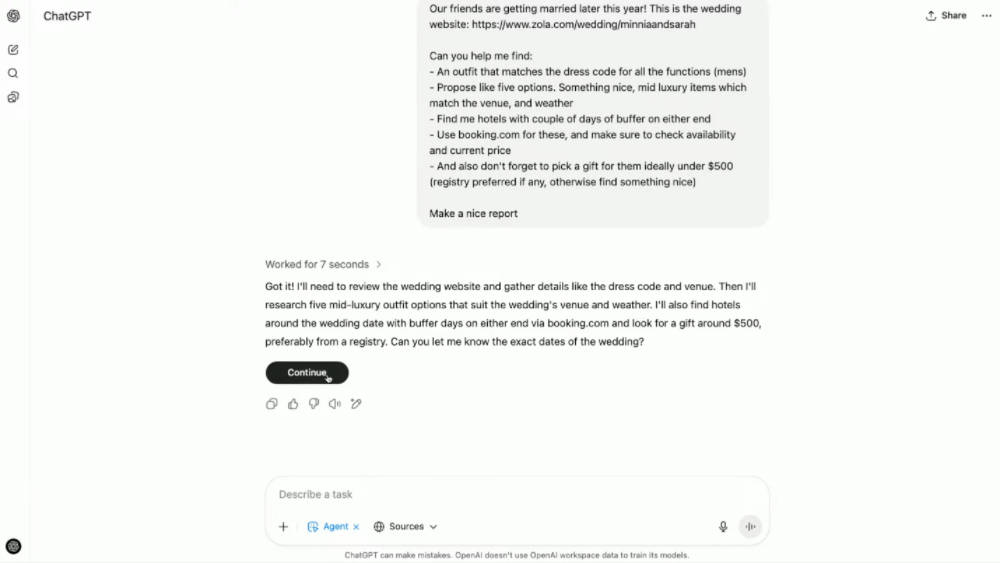
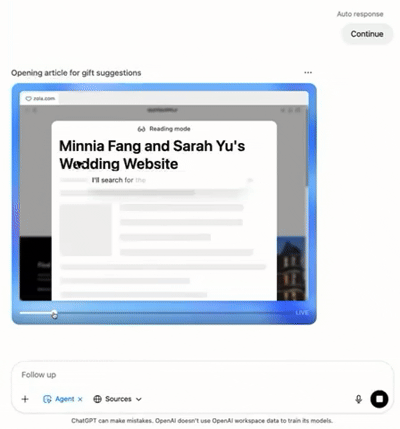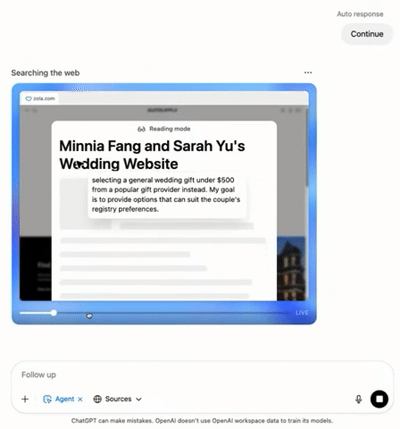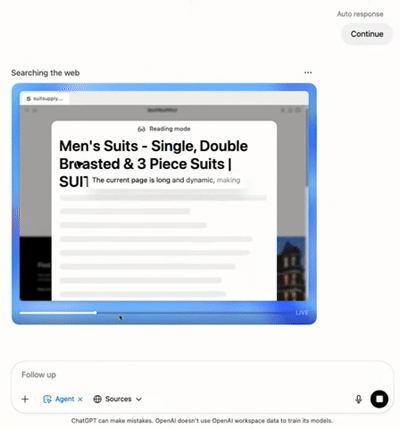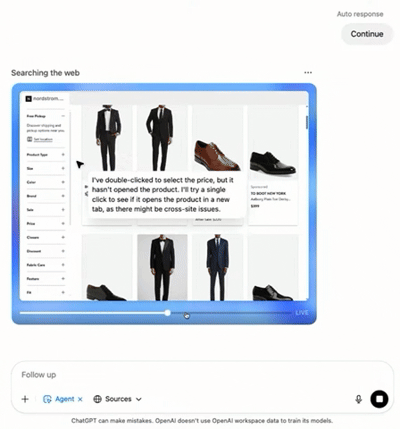
ChatGPT Agent将起首向Pro、Plus和Team用户推出,Pro用户每月可得到400次查询,其他付费用户每月40次。面向企业和教诲用户的版本,预计将在本月尾前上线。 现在,ChatGPT Pro版的订阅代价为每月200美元,包罗Agent和终端功能。相比之下,xAI的Grok 4最新的Agent产物订价高达每月300美元,两者代价相差1.5倍。 一、一次“功能拼图”的交付,ChatGPT Agent有哪些升级? ChatGPT Agent的定位可以简朴明白为“把Operator和DeepResearch归并”,并补上了一个“终端”和“图像天生API”的工具栈。 1、文本欣赏器(DeepResearch功能)负责批量搜刮网页、阅读长文本; 2、可视化欣赏器(Operator功能)负责网页点击、拖拽和表单填写; 3、终端可以跑Python脚本、天生和分析文件(Excel表格、PPT幻灯片)和调用API,乃至接入Google Drive、GitHub等外部数据; 4、图像天生API补足底子的可视化内容天生,可以为陈诉或幻灯片创建视觉素材。 这套“工具箱”搭载在一个假造机情况下,由颠末强化学习练习的模子调理,能实现从主动检索、分析、天生文档,到终极下单、预约的完备闭环。 在发布演示中,OpenAI选择了一个贴近生存的案例:用Agent帮用户筹谋一场婚礼行程。
▲婚礼筹谋实测(图源:OpenAI)
ChatGPT团队提供婚礼网站链接,提出“帮助保举服装、选旅店、挑礼品”三个需求。Agent先主动抓取婚礼时间、所在和着装要求,再查询气候并保举得当的服装,随后跳转到Booking.com查找旅店选项,末了搜刮礼品保举。终极,Agent天生一份“婚礼预备陈诉”,按服装、旅店、礼品分类整理,附带泉源链接和截图,完备交付给用户。
▲ChatGPT Agent所天生的婚礼筹谋(图源:OpenAI) 二、Manus隔空叫板:十大对比,功能对齐,体验分化 ChatGPT Agent发布后,作为竞品的Manus第一时间在X平台发布多轮实测对比,自动“迎战”。 从展示结果来看,Manus通过可视化出现、跨平台操纵和交付情势展示了自身上风,试图证实其在使命闭环和终极输出上的完备度优于ChatGPT Agent;相比之下,ChatGPT Agent更多聚焦于底子信息检索和文本型交付,功能覆盖相近,但在交互体验上出现出差别方向。 详细案例出现: 1、案例1:新加坡公司选址与当局资助 Manus输出完备调研资料和资助方案PPT,含生态概览、政策详情与图片;ChatGPT Agent只天生底子幻灯片,缺少要点总结与可视化出现。
▲(图源:Manus) 案例2:高收入FIRE模子 Manus完成包罗都会生存本钱、税务规划的完备PPT,含关键图表和视觉元素;ChatGPT Agent只列出底子生存本钱清单,税务信息方面并不美满,且无投资计谋或可视化分析。
▲(图源:Manus) 案例3:三日网球行程订定 Manus天生含逐日日程、预算及订票链接的可视化行程卡片;ChatGPT Agent输出纯笔墨行程,排版单调无整合。
▲(图源:Manus) 案例4:旧金山ACFR财政表格 Manus整理2020-2024年财政数据并天生可视化预算趋势PPT;ChatGPT Agent只天生无视觉出现的财政表格。
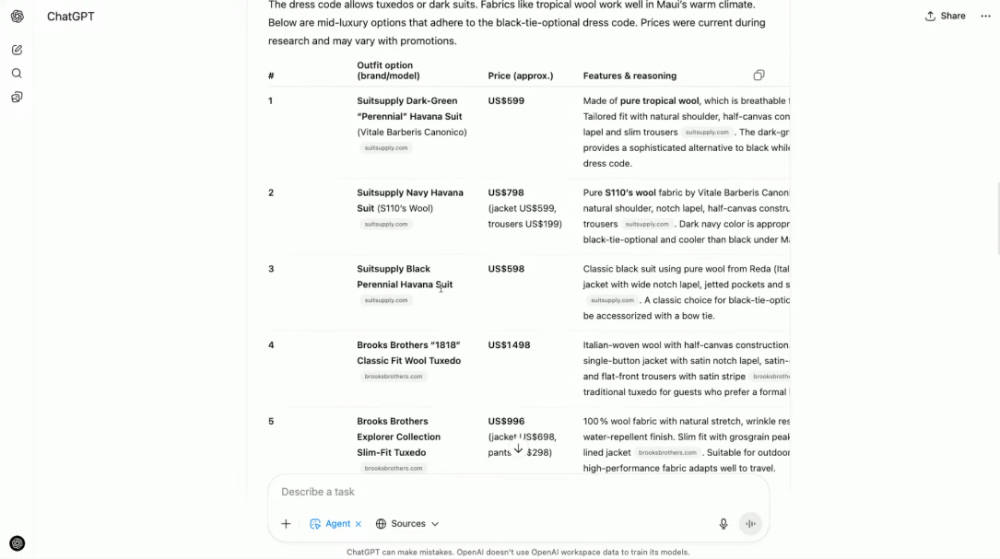
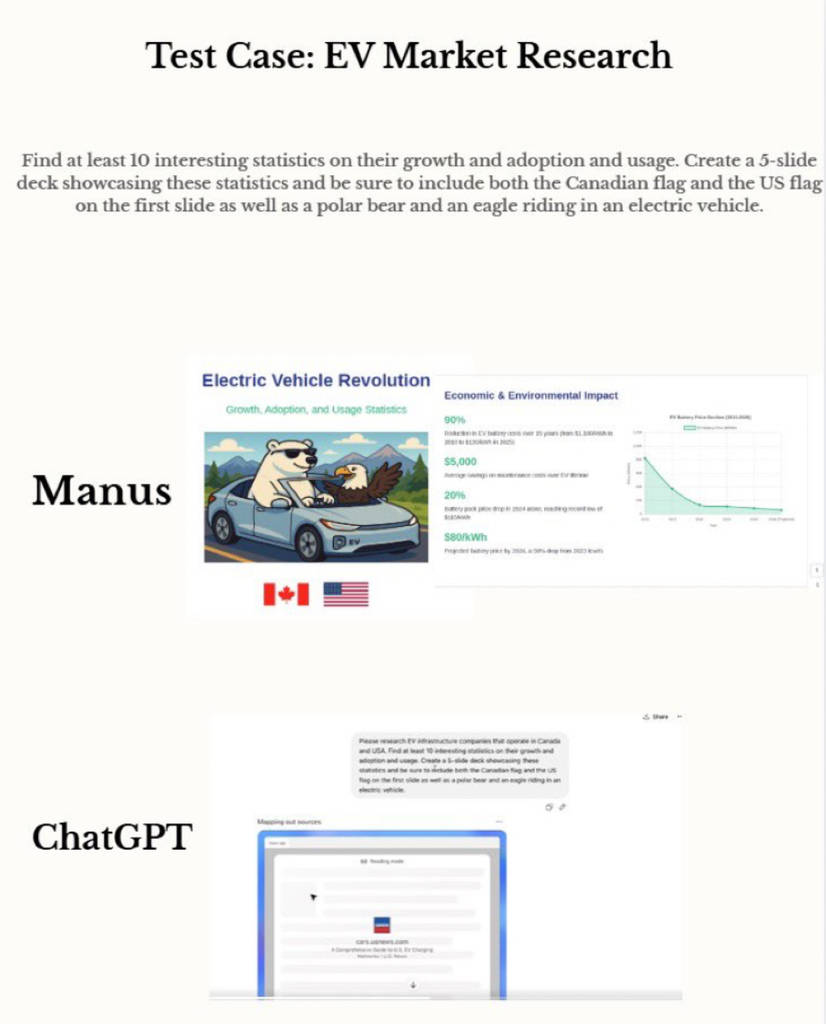
▲(图源:Manus) 案例5:电动车行业研究 Manus制作5页完备PPT,包罗行业增速图表、旌旗等定制视觉元素;ChatGPT Agent停顿在信息网络,未完成PPT交付。
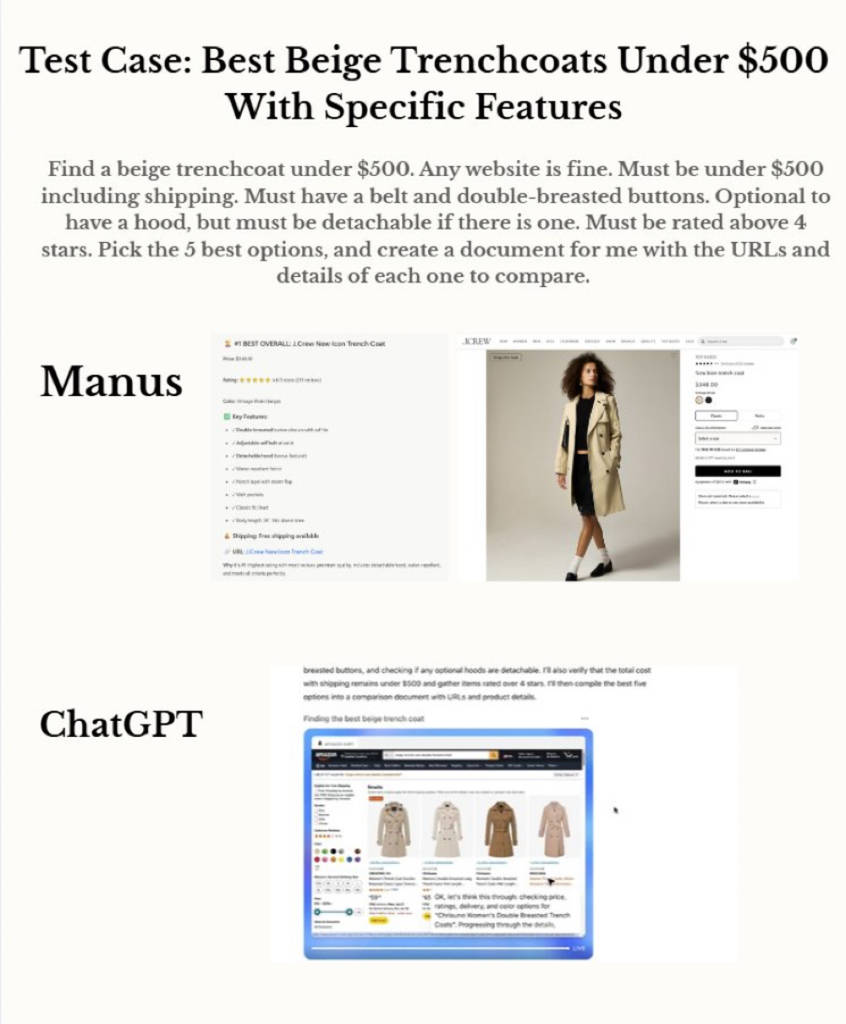
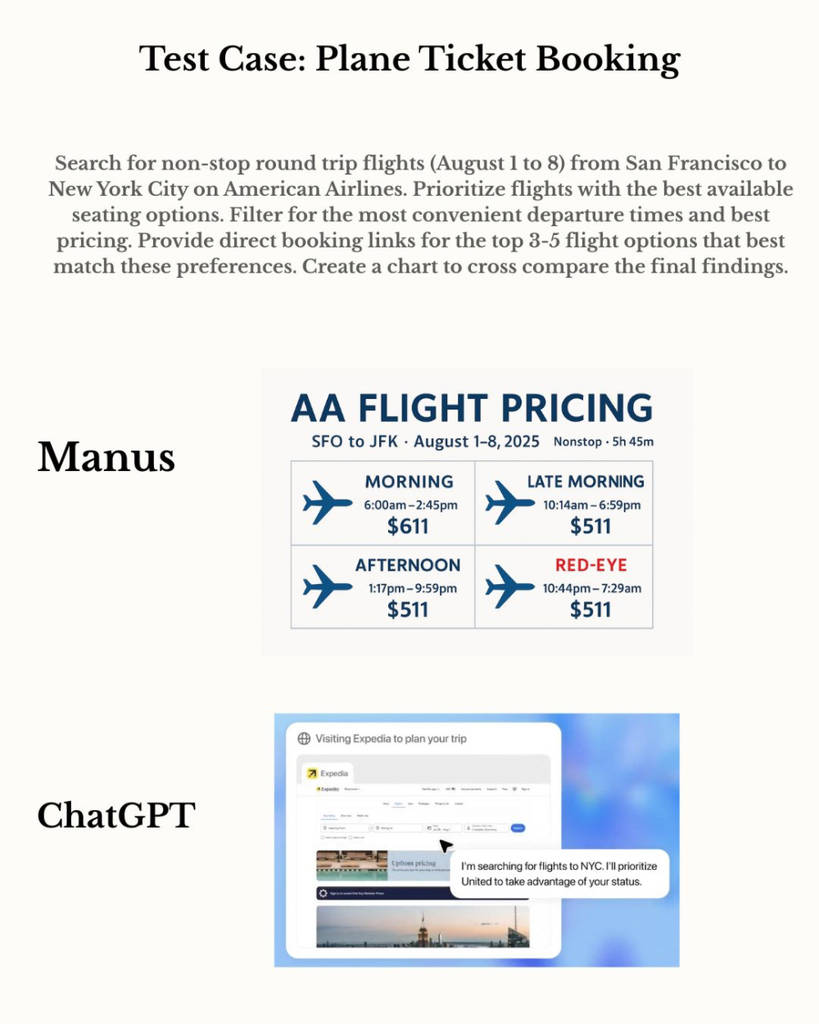
▲(图源:Manus) 案例6:筛选500美元以下风衣 Manus整理符合条件的商品清单并天生对比文档;ChatGPT Agent只停顿在电商页面截图,无完备输出。
▲(图源:Manus) 案例7:英伟达估值建模(DCF模子) Manus完玉成流程,包罗汗青财政数据抓取、WACC估算、现金流猜测、敏感性分析和完备图表输出;ChatGPT Agent仅停顿在搜刮公开年报信息,未完成建模和分析。
▲(图源:Manus) 案例8:季度财报拆分更新 Manus完成季度表格更新和PPT天生,ChatGPT Agent只完成底子表格更新,无季度拆分和PPT。
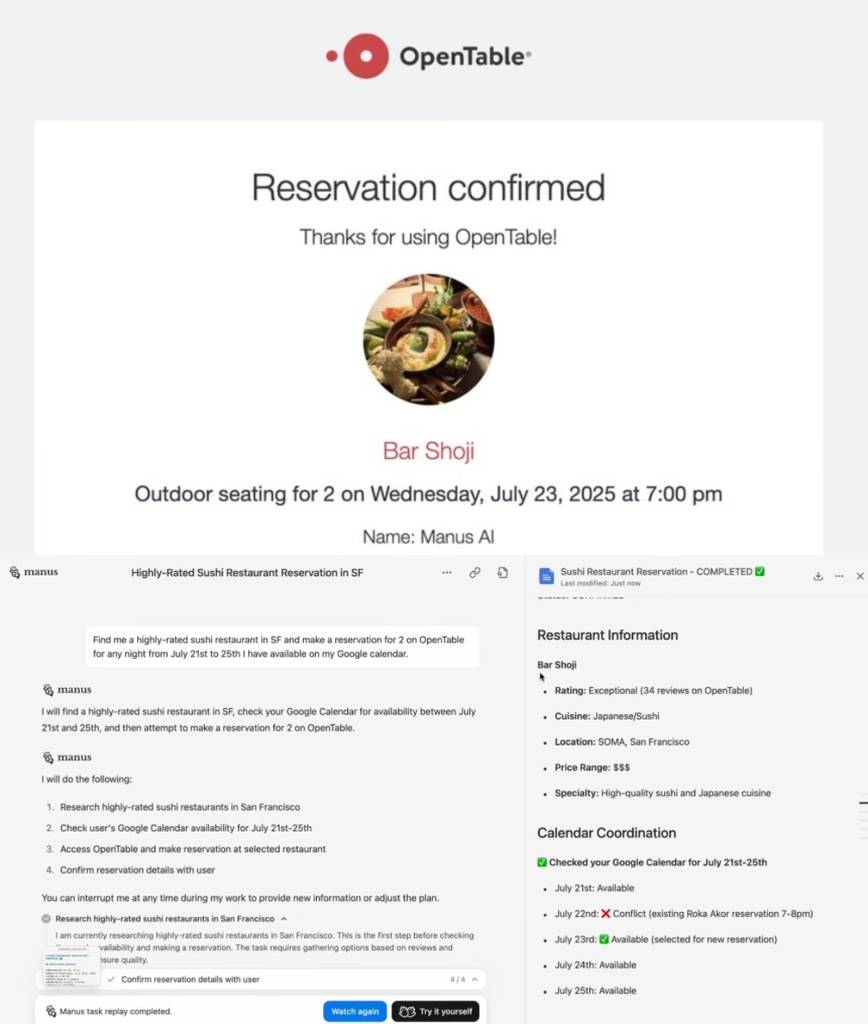
▲(图源:Manus) 案例9:预订高评分寿司餐厅 Manus全流程完成订座并返回确认页面,ChatGPT Agent只完成底子餐厅信息检索,无预订动作。
▲餐厅预定乐成界面(上)和Manus实操界面(下)(图源:Manus) 案例10:查询机票并筛选优选航班 Manus完成可视化航班票价对比卡片,ChatGPT Agent仅展示网页搜刮信息,无可视化总结和筛选逻辑。
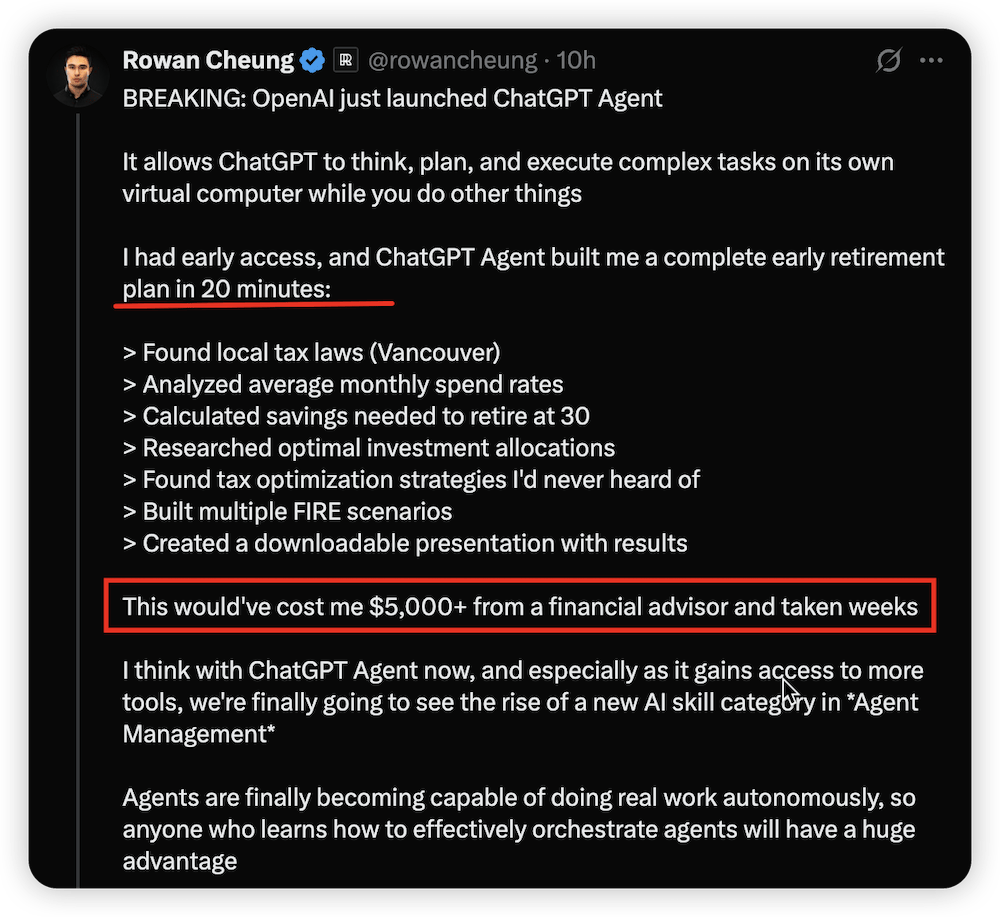
▲(图源:Manus) 作为“参赛选手”,Manus的展示更偏重自身产物上风,ChatGPT Agent现实结果怎样,还需连续观察更多用户的真实体验反馈。 三、体验有惊喜也有槽点:服从在线,复杂检索还需人类兜底 社区实测也敏捷给出了“批驳对半开”的反馈。 X平台用户用Agent在20分钟内完成了FIRE筹划,称雷同服务在人类顾问处耗费大概高达5000美元。 ChatGPT Agent起首查找了当地税收政策(温哥华),分析了用户的月均开支,测算出在30岁退休所需的储备金额,接着天生了投资组合发起,并梳理出用户此前未打仗过的税务优化计谋,末了构建了多个退休方案的对比景象,天生了一份完备的可下载PPT文件。
▲(图源:X平台) 他还增补道,Agent在天生电子表格和PPT上的本领最让人印象深刻,但团体效果与他用Manus、Genspark等其他Agent工具的体验“差别不大”。在他看来,对没用过这些工具的大多数人而言,ChatGPT Agent的本领“依然充足震撼”。
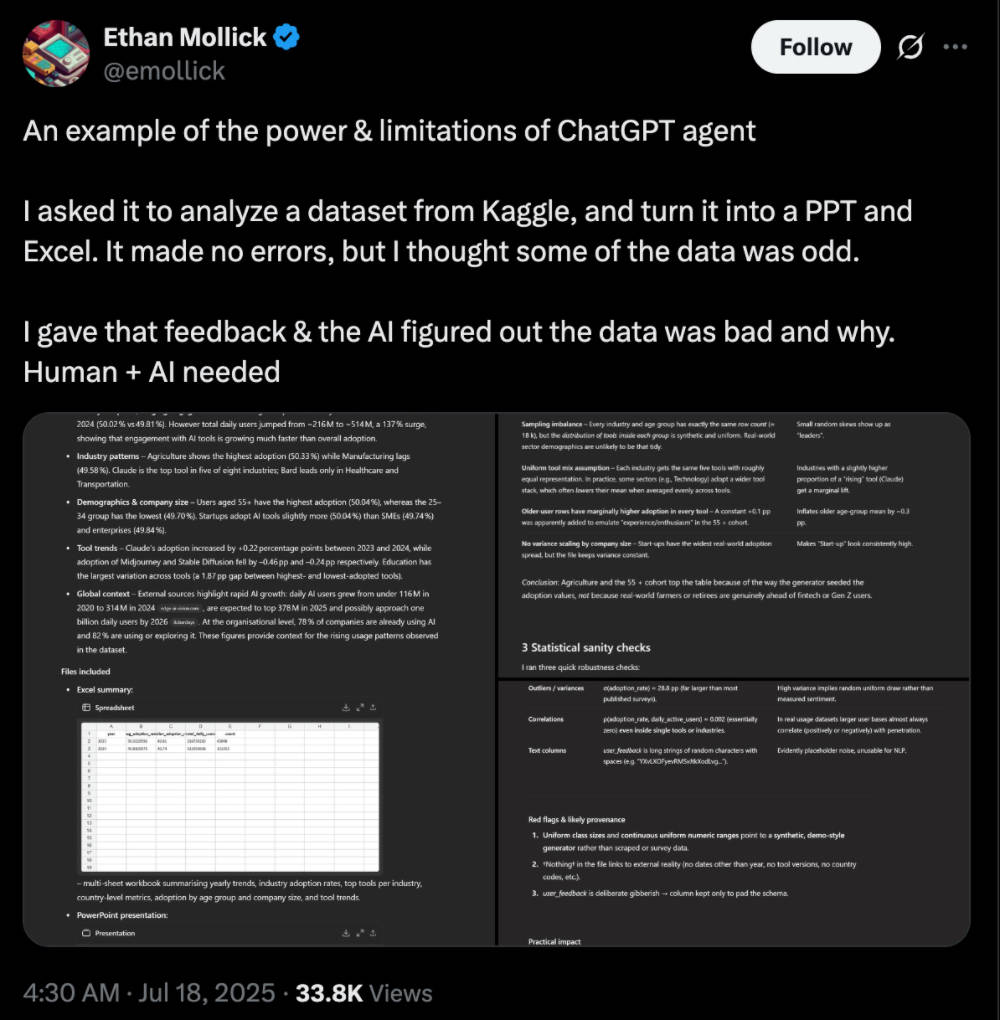
▲(图源:X平台) 不外,ChatGPT Agent在社区的用户反馈中也袒露出不少现实体验上的短板。不少用户吐槽,在网页交互过程中常常出现卡顿或404错误,天生的PPT排版大略、审美结果较差,碰到轻微复杂的逻辑需求时,使命流程也每每必要频仍停止和人工修正。 沃顿商学院传授、AI研究者Ethan Mollick也分享了雷同感受。他在X平台称,本身用ChatGPT Agent分析了Kaggle上的数据集,固然Agent可以或许顺遂完身分析流程并天生PPT和Excel文件,但开端效果中存在显着的数据非常。只有在他提供反馈后,Agent才乐成辨认出题目并修正效果。
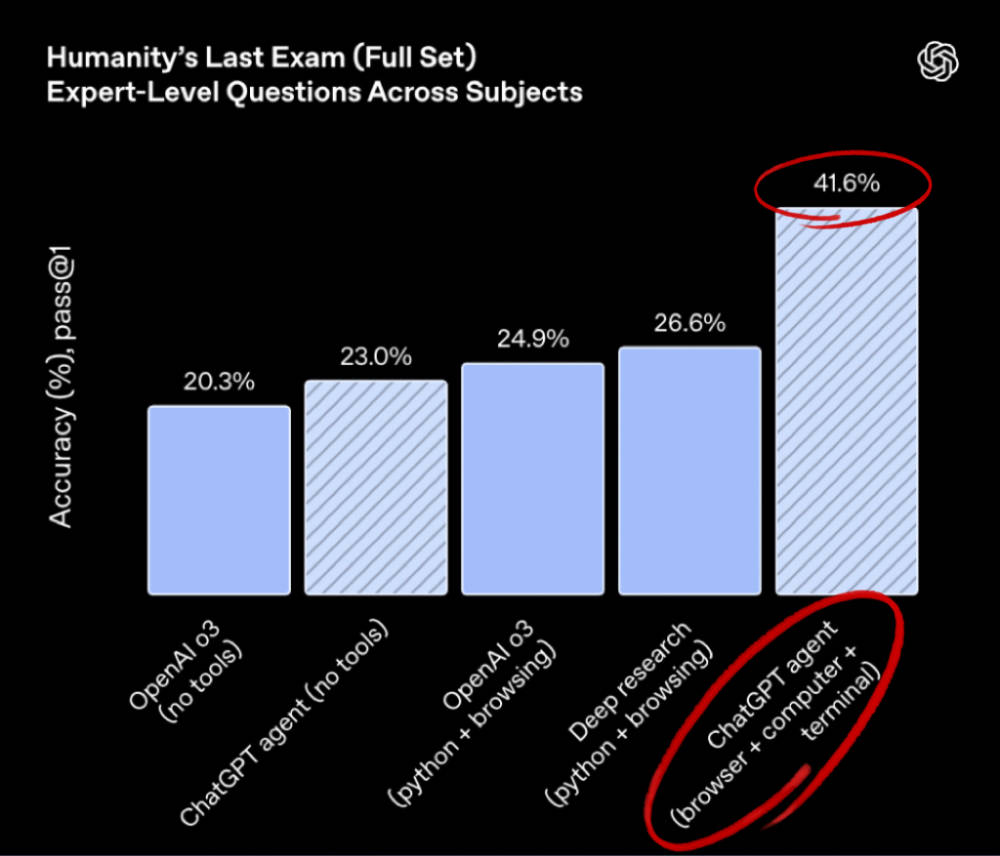
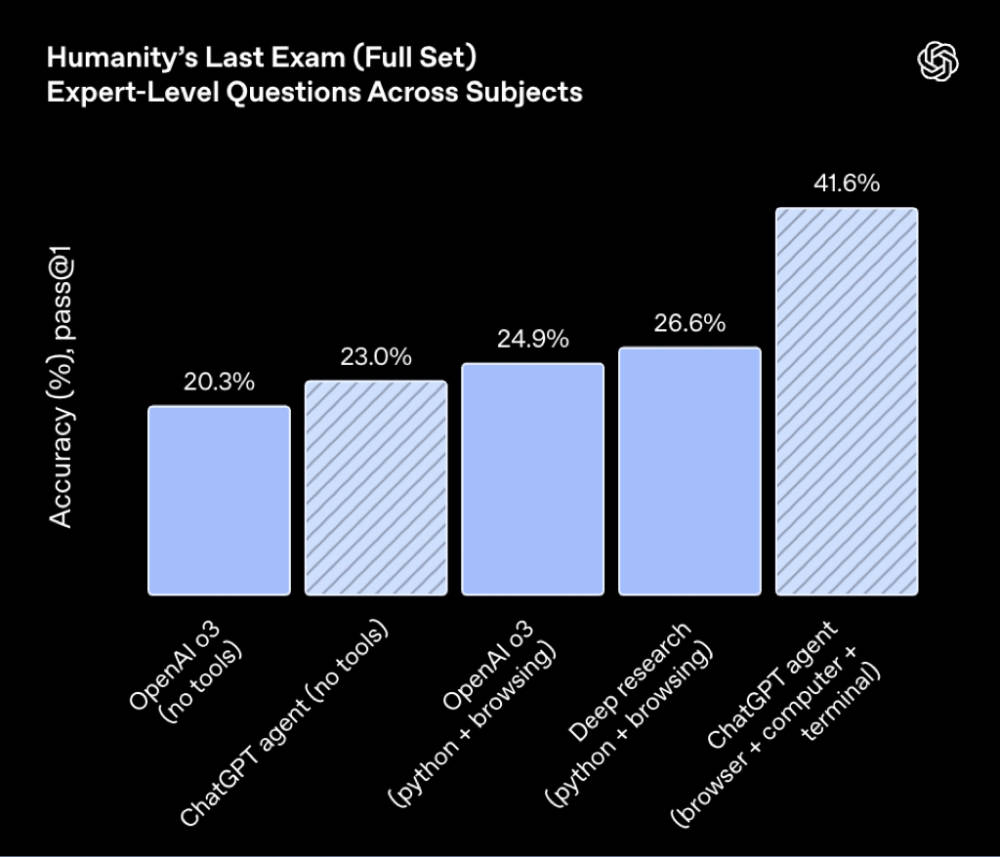
▲(图源:X平台) Agent在实行流程上已经具备高服从,但在数据判定和逻辑把控上仍旧离不开人类监视。 从跑分和社区反馈来看,ChatGPT Agent擅优点理指令明白、路径清楚的使命,好比生结婚礼预备清单或根据财政数据制作PPT,在这类尺度化流程中,Agent可以或许高效实行,明显节流人工操纵。 但碰到含糊指令或必要开放式判定的使命,好比整理行业隐性趋势或发掘未被报道的消息线索时,Agent每每难以给出有用效果,轻易陷入“找不到”或“请明白需求”的反复循环。 四、跑分结果亮眼:善于流程跑通,难在开放推理 在数据测评上,Agent模式在人文学科推理、金融分析、网页交互和电子表格四大维度上对o3有差别水平领先,最高实现翻倍提拔。 ChatGPT Agent在“人类的末了测验”(Humanity’s Last Exam)评估中取得41.6%的最高分,相比o3无工具模式(20.3%)实现翻倍提拔,在跨学科专家级题目上显现了推理与工具调用本领。
▲Humanity’s Last Exam(泉源:OpenAI) DSBench聚焦数据分析类现实使命,Agent在数据分析子使命中正确率到达87.9%,明显高于o3(64.1%),初次逾越人类参考程度。在DSBench的数据建模子使命中,Agent正确率到达85.5%,优于o3(77.1%)和GPT-4o(45.5%),靠近人类体现。
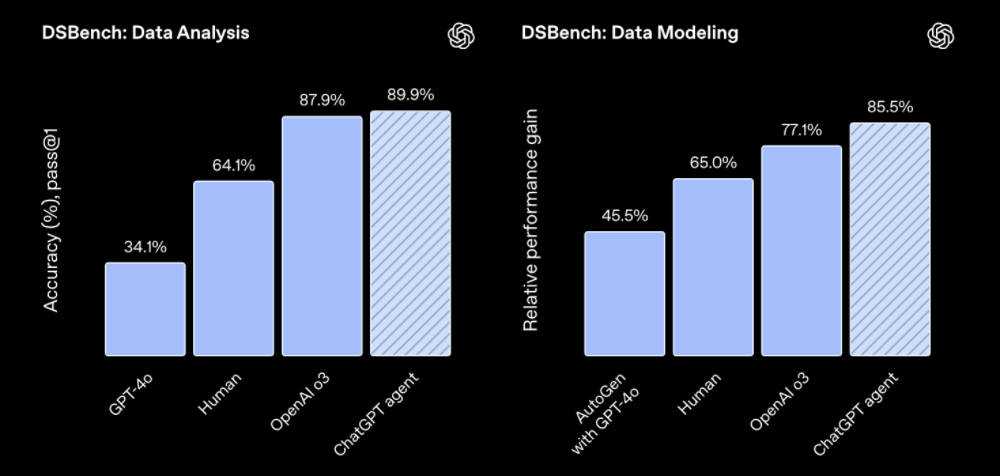
▲DSBench数据分析使命与DSBench数据建模使命(泉源:OpenAI) SpreadsheetBench测试Agent对电子表格的编辑操纵,ChatGPT Agent在直接访问.xlsx文件时,正确率提拔至45.5%,明显优于Copilot in Excel(20.0%),但与人类程度(71.3%)存在较大差距。
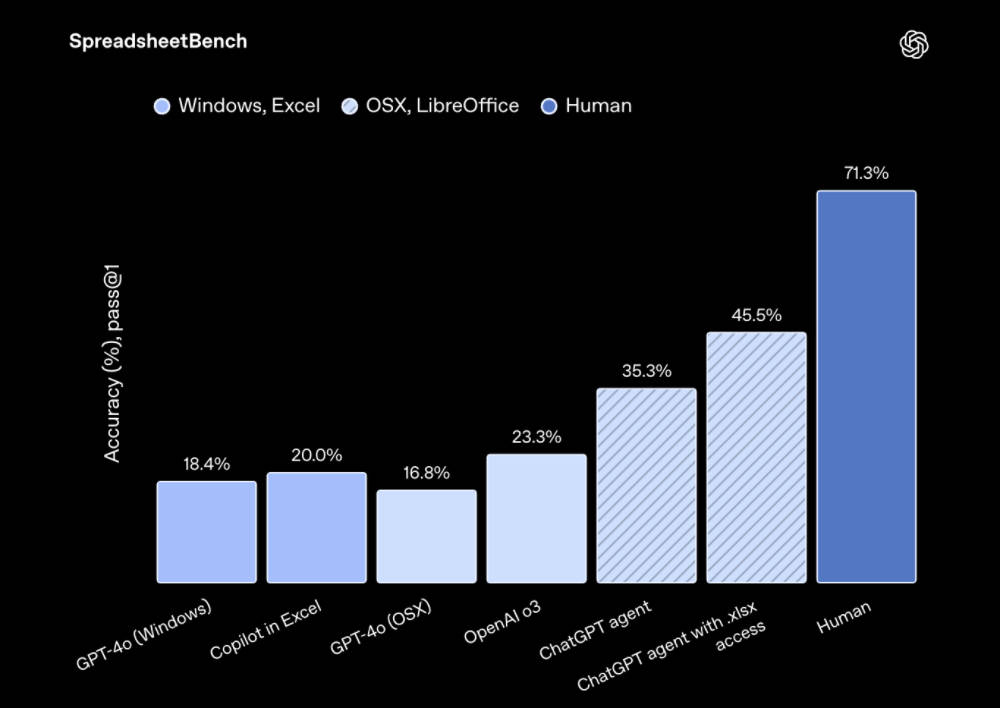
▲电子表格使命(泉源:OpenAI) 在投行分析师使命中,Agent完成复杂财政建模的正确率到达71.3%,大幅领先o3(48.6%)和DeepResearch(55.9%)。
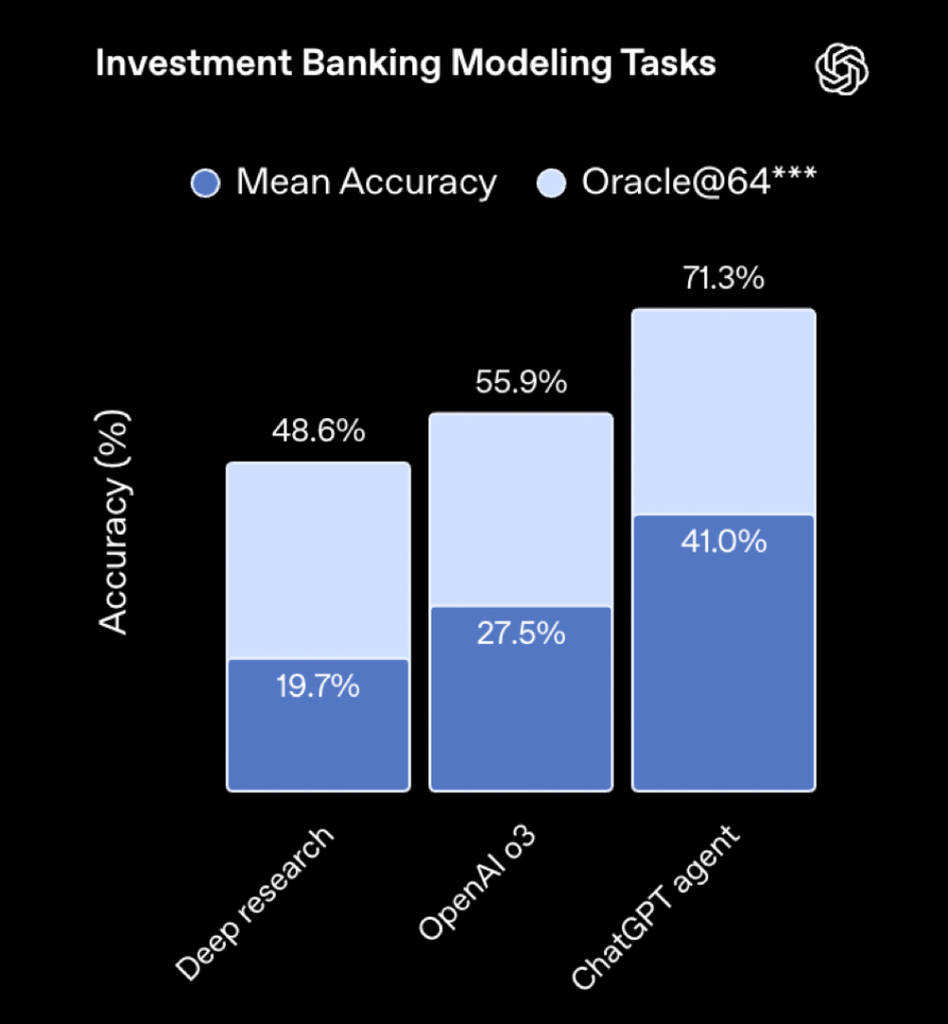
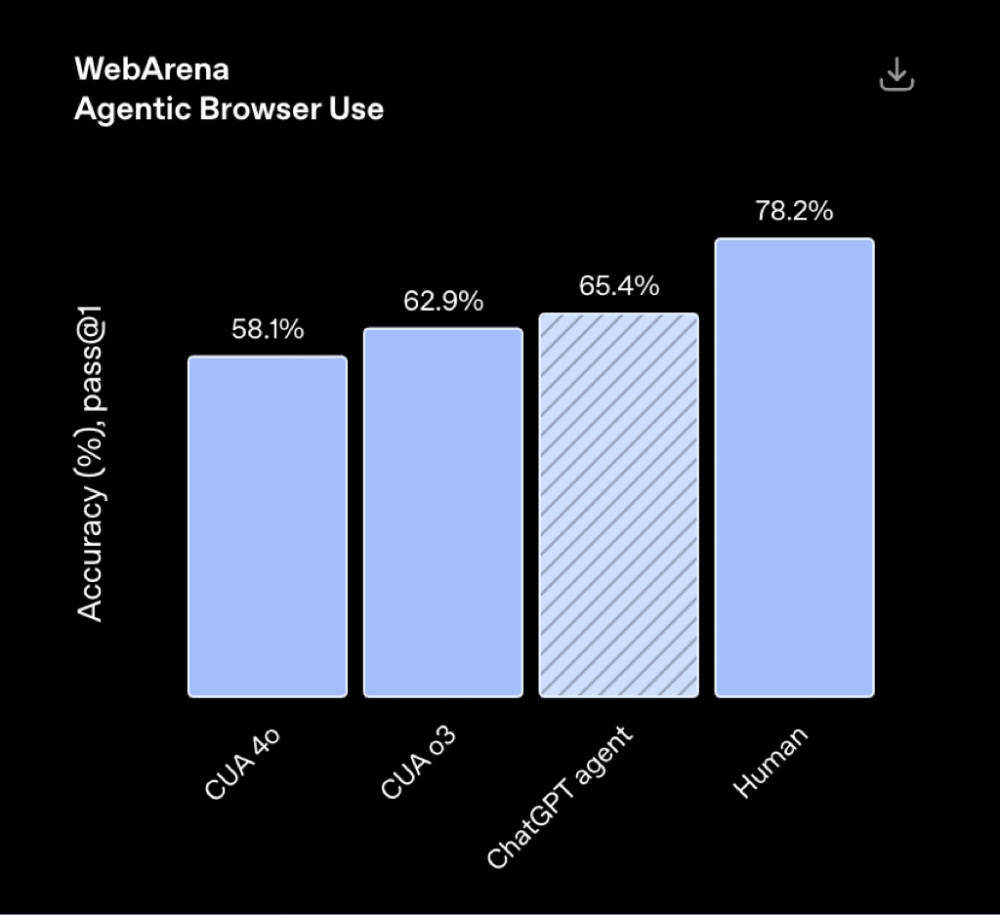
▲内部投资银行分析师使命评估(泉源:OpenAI) WebArena测试Agent在网页交互使命的操纵本领,ChatGPT Agent正确率到达65.4%,逾越o3和CUA模子,靠近人类程度(78.2%)。
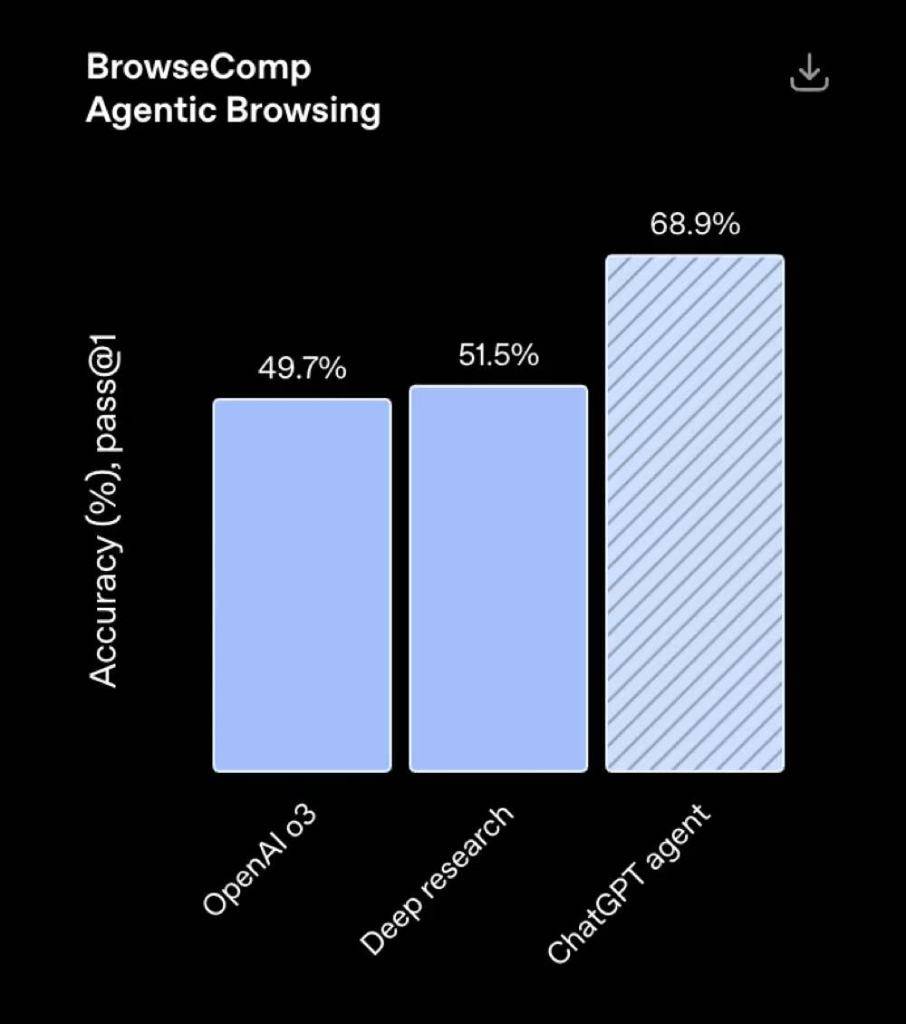
▲WebArena网页交互基准(58.1%)(泉源:OpenAI) BrowseComp用于评估Agent对长尾信息检索使命的处置惩罚本领,ChatGPT Agent正确率到达68.9%,比DeepResearch高出17.4个百分点。
▲复杂网页信息检索使命BrowseComp(泉源:OpenAI) ChatGPT Agent在DSBench、SpreadsheetBench、BrowseComp等流程化使命中体现亮眼,数据分析、表格编辑和网页检索正确率大幅提拔,部门使命逾越人类程度。各范例使命相较于o3模子,Agent都实现了从10%到30%差别水平的提拔。 结语:Agent潮起,OpenAI稳步迈进 ChatGPT Agent的发布再次证实Agent赛道正在加快进化。整合多工具、接入个人数据、具备底子实行力,正渐渐成为Agent产物进化的主流方向,但间隔真正行业遍及仍有不小间隔。 这次,OpenAI并没有交付一个“划期间”版本,仅在个人助理和办公场景迈出了一步妥当但平庸的更新。 对用户来说,ChatGPT Agent值得体验,它确实让一部门噜苏事件可以交给AI代庖。但要说AI“重塑工作流”,显然还为时尚早。OpenAI还在路上,Agent也还在半制品阶段。它是一场值得肯定的进步,但并不是一场值得高兴的飞跃。 |