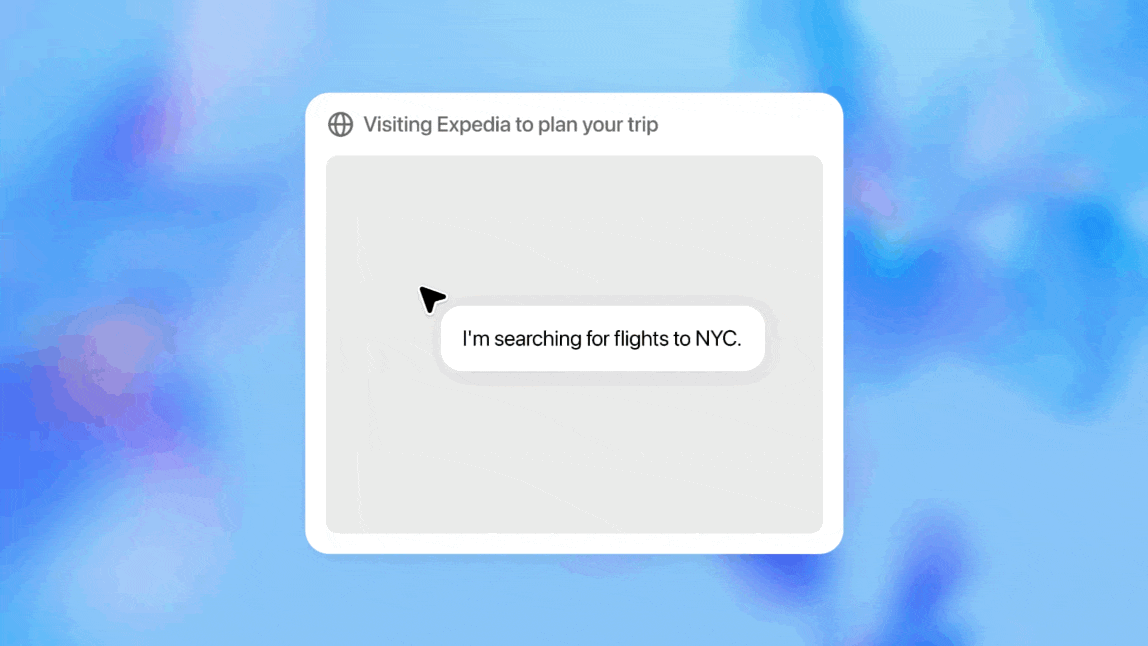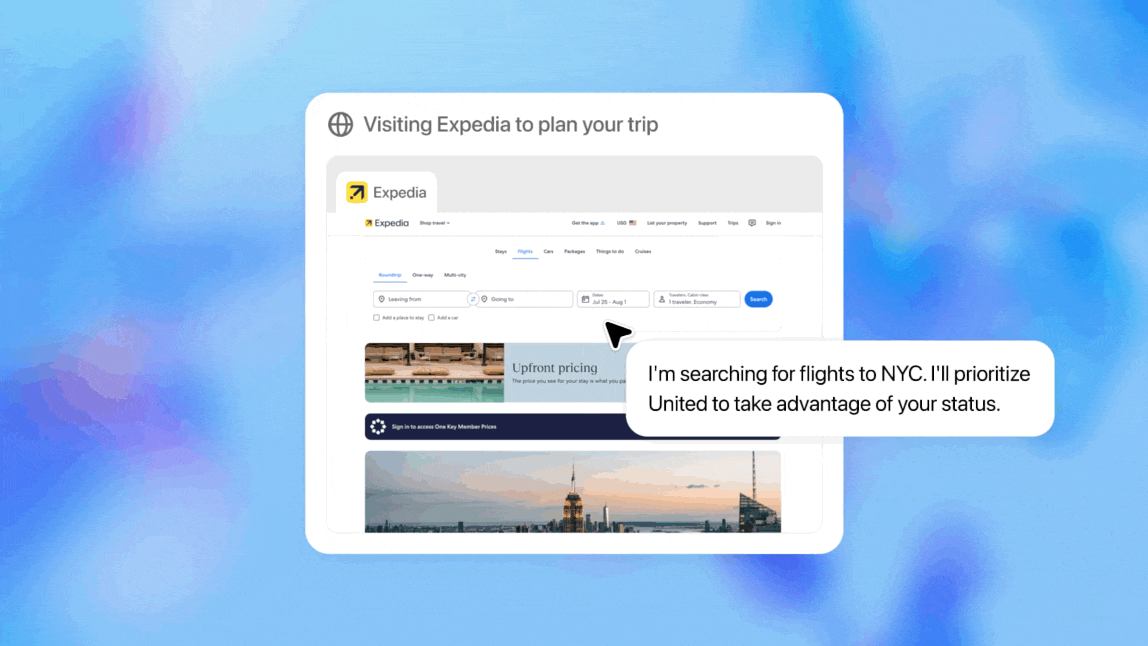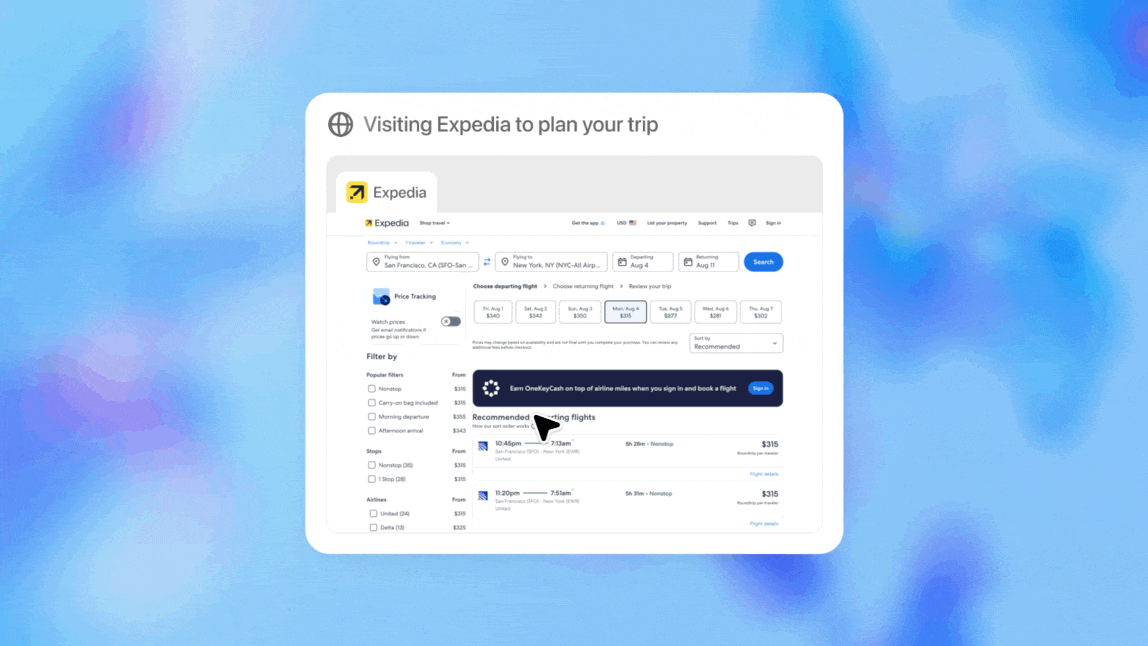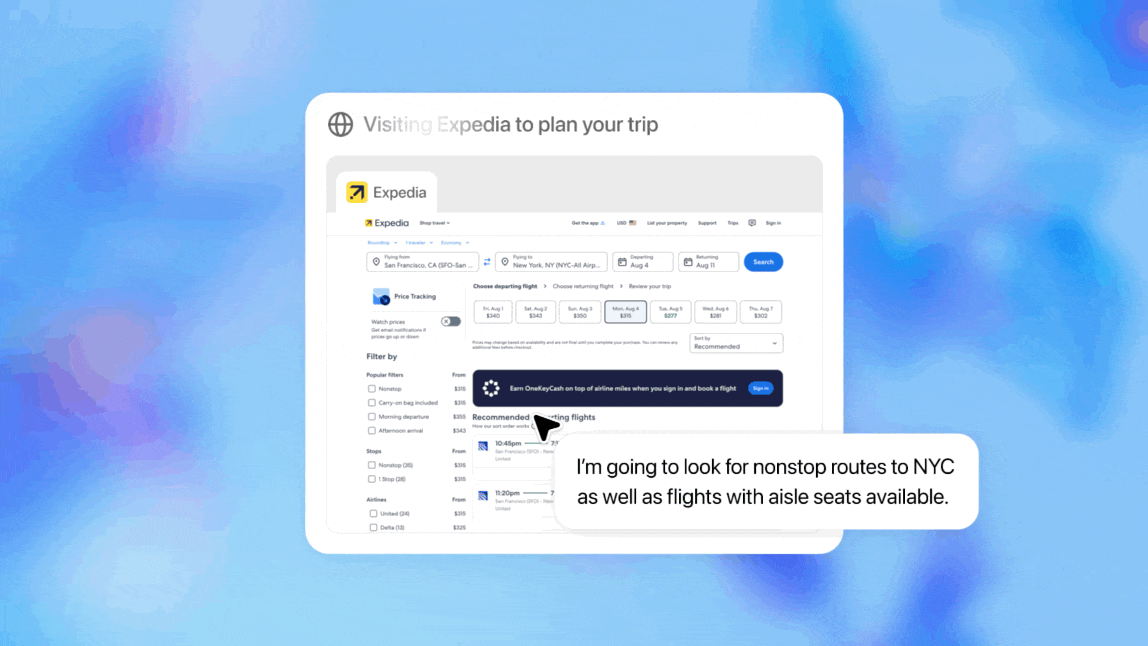
文|晓静 编辑|萌萌 发布会回放:OpenAI推出ChatGPT智能体,可控制整个盘算机实行使命 Agent是本年AI圈最大的共识,OpenAI天然也不能落后。 北京时间2025年7月18日破晓1点,Sam Altman 和四位OpenAI 的研究员在直播中正式发布了ChatGPT Agent——一款通用型 AI Agent。
前有Manus、Lovart和Flowith,ChatGPT Agent 所出现的功能场景并不算特殊惊艳,但它发布的意义,要逾越其功能自己。 ChatGPT Agent的革命性在于其独特的技能路径:它可以自动从工具箱中选择署理技能,利用本身的盘算机完成使命,用户可以及时观察AI在假造情况中的工作过程。 这种交互界面虽与Manus等产物相似,但底层原理却有着本质差别。Manus调用多个底层模子,雷同于“外部缝合”,而ChatGPT Agent,是将Agent本领内化于模子,昨们已经看到了端到端通用Agent的雏形。
OpenAI先容,为了开辟ChatGPT Agent,他们将Operator和Deep Research团队归并为一个同一的团队,这个新团队由20至35人构成。 根据ChatGPT Agent的体系卡片表现,这是一个新的署理模子,与OpenAI o3同属一个系列,接纳了端到端的练习方法。它是为署理使命开辟的同一模子,而不是多个模子的工程化组合。
Agent联合了Deep research的多步研究和高质量陈诉天生本领、Operator通过长途可视化欣赏器情况实行使命的本领、具有有限网络访问权限的终端工具,以及通过毗连器访问外部数据源和应用步伐的本领。 在实行完复杂使命之后,也可以交付给用户一个可下载的PPT或文档。 对Manus而言,OpenAI的这一新办法无疑是巨大的打击,乃至从订价上,两者也差距不大:GPT的Plus套餐每月20美金即可利用Agent,而Manus的底子筹划是每月19美金。 划重点:
一、ChatGPT Agent概览:功能很像manusChatGPT Agent的焦点是一个同一的署理体系 (unified agentic system),整归并扩展了 OpenAI 早期研究项目 "Operator"(偏重于网站交互)和 "Deep Research"(偏重于信息综合)的本领。 这使得 ChatGPT Agent 可以或许在一个单一的对话流中,无缝地从推理思索切换到实行详细动作。 假造盘算机情况:ChatGPT Agent在一个为其特设的假造盘算机上实行全部使命。这个情况是沙盒化的,确保了操纵的安全性。它可以或许在该情况中生存使命的上下文,纵然用户中途打断或改变指令,也能从断点继承,而不会丢失进度。 智能工具箱:为了完成复杂工作流,Agent 配备了四种工具,并能根据使命需求主动选择最符合的工具:
新模子驱动:ChatGPT Agent由一个专门为其开辟的新模子驱动。这个模子通过强化学习 (reinforcement learning) 的方法,在必要利用多种工具的复杂使命上举行了专门练习,从而学会了如安在差别工具之间流通切换并协同工作。 它有以下特性: 自主使命实行: 用户可以用天然语言下达指令,比方“分析我的日历,并根据近来的消息为我简报即将到来的客户集会”,Agent 可以或许自主规划并实行一系列操纵,如欣赏网站、筛选信息、运行代码分析,并终极天生可编辑的幻灯片或电子表格等结果。
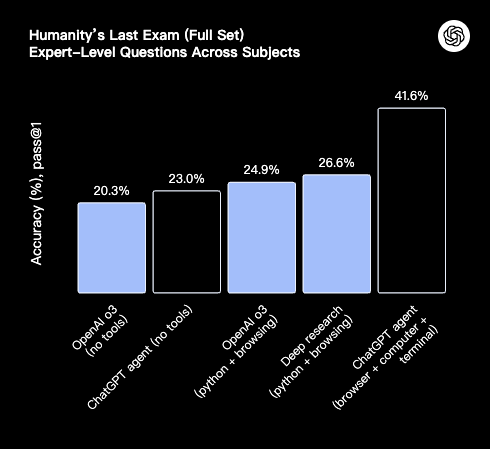
协作与交互性: 它会在必要时自动扣问更多细节以完成目的。用户可以随时停止、重定向使命或完全接受欣赏器的控制权。 安全与权限控制: 安全性是其计划的焦点部门。在实行购买、提交表单、发送邮件或处置惩罚个人信息等具有现实影响的关键操纵前,Agent 会明白哀求用户允许。同时,它被克制实行如金融转账或提供法律发起等高风险使命。OpenAI 还内置了针对“提示注入”等恶意攻击的防护步伐。 二、多项基准测试跑分“破记录”最难的 HLE 到达 41.6%(with tool), 高于刚刚发布的Grok4(with tool)41.0%。 在评估广域知识与专家级提问的 Humanity’s Last Exam 上,单次作答正确率达 41.6%;接纳并行八路推理并选取置信度最高答案后可提拔到 44.4%。
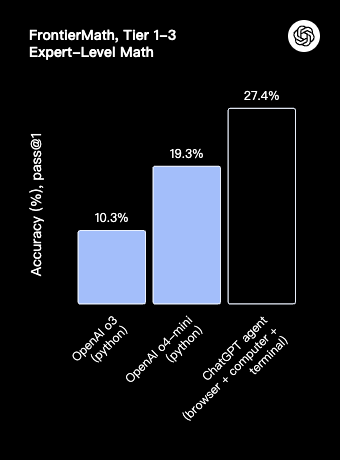
在极难的 FrontierMath 数学基准上,借助终端运行代码后正确率提拔至 27.4%。
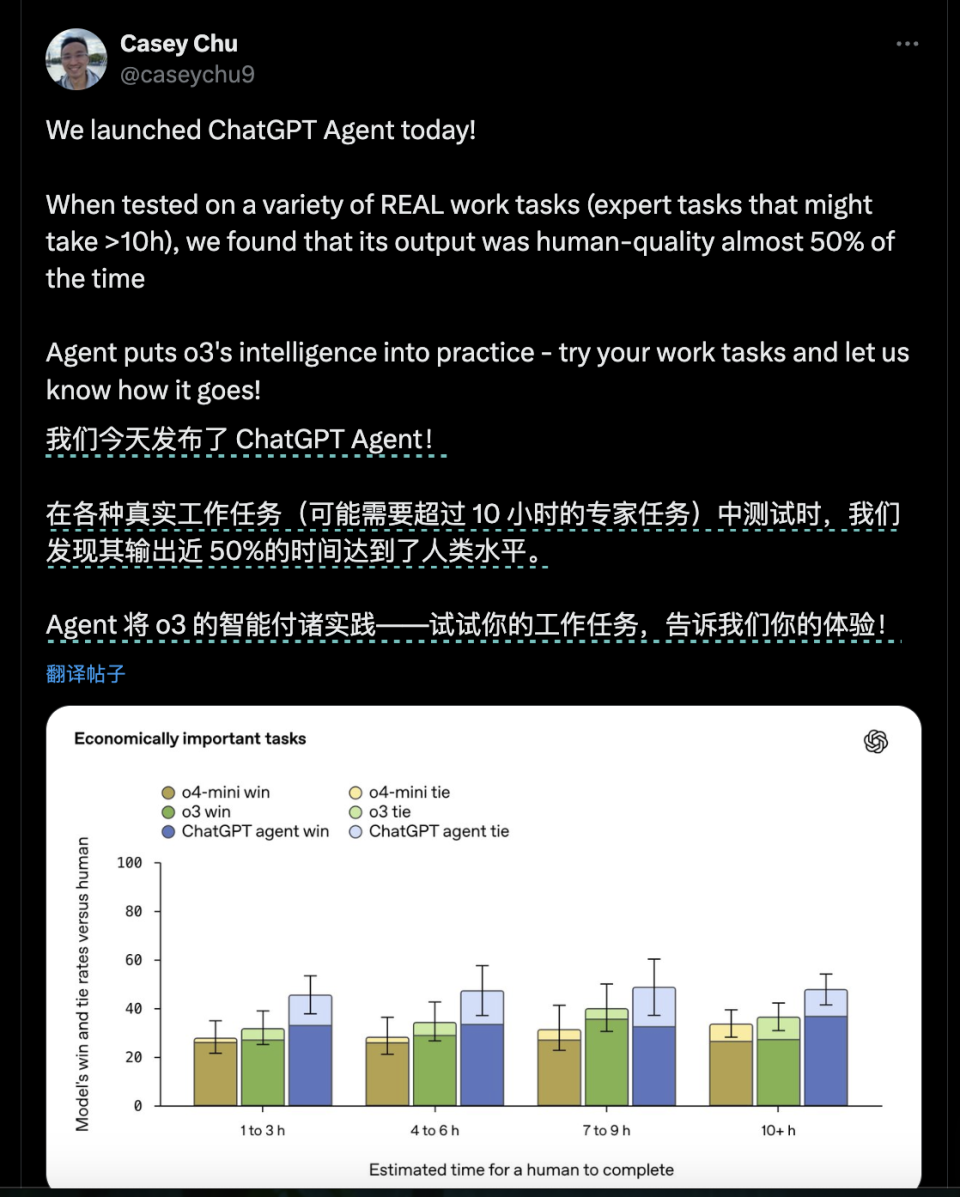
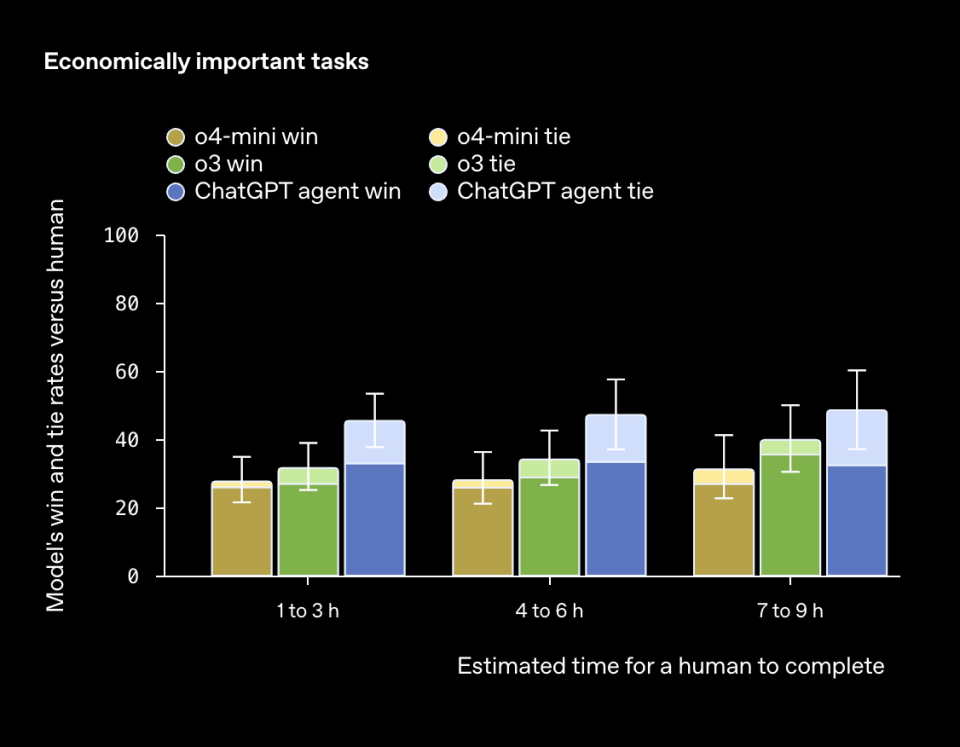
在针对真实知识工作使命的内部评测中,ChatGPT 署理在约半数案例里已与人类持平或更佳;
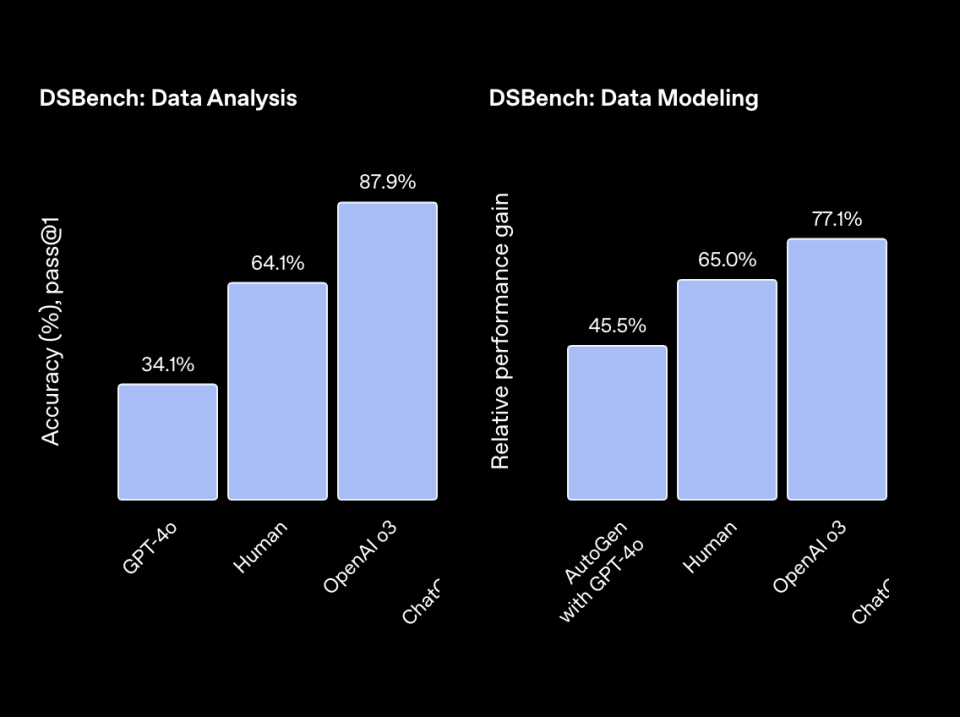
在实际数据科学使命 DSBench 上,其分析与建模正确率分别到达 89.9% 与 85.5%,远超人类均匀程度。
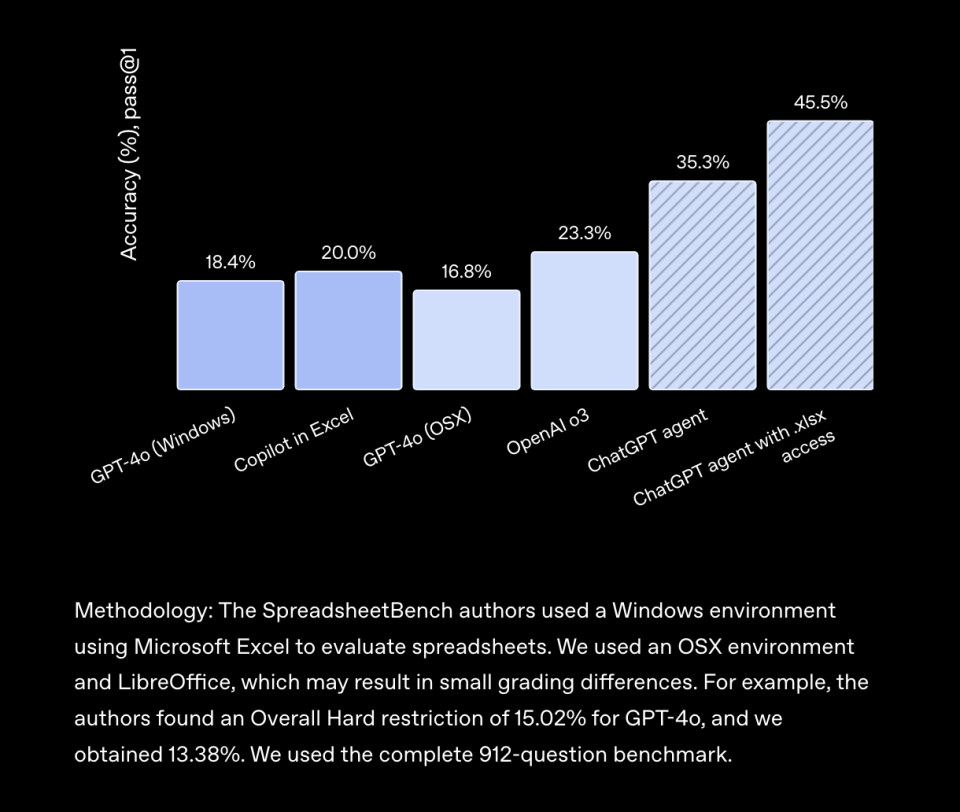
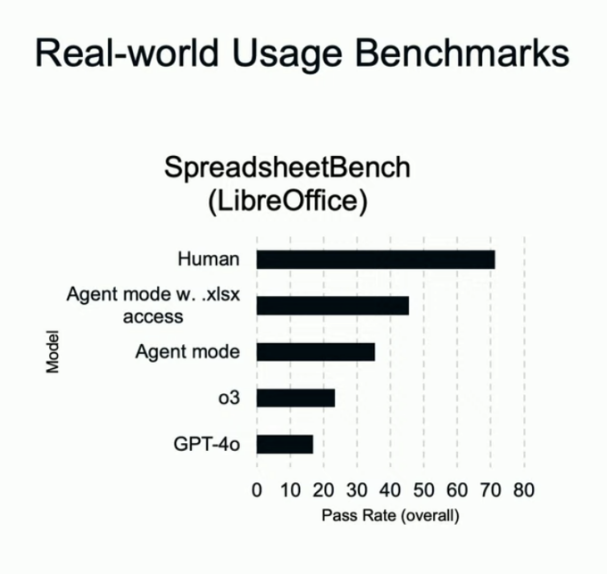
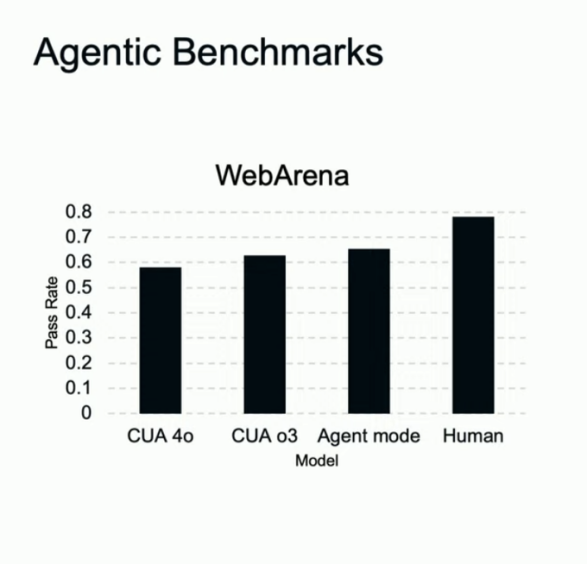
它对电子表格的直接编辑本领也领先:在 SpreadsheetBench 中拿到 45.5%,凌驾 Copilot in Excel 的 20%。别的,它在 BrowseComp、WebArena 等欣赏评测里均革新了SOTA。
(图:评测方法:SpreadsheetBench的作者在Windows 情况下利用 Microsoft Excel 对电子表格举行评估。昨们则在 OSX 情况中利用 LibreOffice,这大概导致评分出现稍微差别。比方,作者陈诉 GPT‑4o 在团体 Hard 限定上的效果为 15.02%,而昨们得到 13.38%。昨们利用了完备的 912 道标题基准测试。) 根据ChatGPT Agent本身做的PPT,在做PPT的本领上和上网冲浪本领上,Agent的本领都相比纯粹的底子模子有较显着的提拔。但离人类还颇有间隔。
三、不是期货,本日可用自本日起,Pro 用户可以立刻利用,Plus 与 Team 用户将在数日内连续开通;Enterprise 与 Education 版本将于数周后接入。 Pro 每月可用 400 条消息,其他付费用户每月额度为 40 条,可通过机动的按量计费追加。 现实利用非常简朴:在任何对话中切到「署理模式」,形貌目的,比方深度调研、制作演示或报销。屏幕左侧及时表现它的操纵流程;若必要登录,体系会切换到「接受模式」安全输入凭据。 用户还可以把完成的使命设为周期性实行,比方每周一主动天生指标陈诉。 四、奥特曼亲身提示风险:Agent很强盛,也很伤害值得留意的是,奥特曼在发布会之后,立即发了一条长贴,提示利用ChatGPT Agent的风险。 在“夸大”过ChatGPT Agent处置惩罚复杂使命的强盛本领后,特殊谨慎地提示了产物的风险,并夸大:昨们尚不清晰详细会造成什么影响,但非法分子大概会试图“诱骗”用户的 AI 署理提供不应提供的私家信息并接纳不应接纳的举措,而这此中的方式昨们无法猜测。 模子大概会打仗用户的敏感数据,或遭遇网页中的恶意「提示注入」攻击。为此,他们相沿 Operator 期间的严酷控制,并新增多项防护:
在生物与化学安全方面,OpenAI根据 Preparedness Framework 将该模子按高风险级别处置惩罚,上线了最全面的安全步伐,并与当局、学界及安全机构互助开展红队测试与威胁建模,同时启动毛病赏金筹划,以便尽早发现并修补潜伏题目。
五、ChatGPT Agent够遥遥领先吗?ChatGPT Agent最大的创新在于初次在模子中直接集成了完备的假造机情况,用户可以及时观察AI的操纵过程,这是别的模子产物不具备的。 但是,各主流模子公司都在“Agent即模子,模子即Agent”的路上越走越远。好比,在coding agent本领上险些封神的Claude。 浩繁必要借用底层模子搭建的Agent产物,乃至脱离了Claude,就什么也不是。 刚刚上线的Kimi K2接纳开源的混淆专家模子架构,定位就为Agentic Intelligence,且代价仅有Claude 4的1/6左右。上线之后,token的接纳量排名连续飙升。 但从“模子即Agent”这条路来说,OpenAI并不能算是遥遥领先,仅仅能说迈出了一小步。 OpenAI在官方文档中也特殊谦善地表现: 必要留意的是,功能仍处早期:比方幻灯片生乐成能现为 beta,格式与雅观度仍待提拔,现阶段重要优化信息布局与元素可编辑性;将来昨们将继承练习新版本,以天生更风雅的文件。总的来说,随着连续迭代,ChatGPT 署理的服从、深度和多样性都会不停提拔,昨们也会渐渐调优用户监视的力度,在易用与安全之间取得更好均衡。
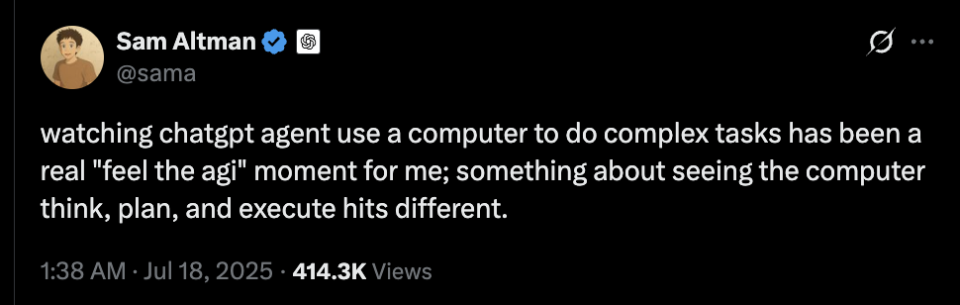
看着自家产物的演示,Sam Altman不禁又开始感叹:“我感受到了AGI。” 然而,在帖子下方照旧有长长的用户留言追问:“说好的GPT-5呢?”
|